
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 파이썬 sep
- 파이썬 int()
- 파이썬 |
- 파이썬 map 함수
- 99클럽
- fatal:not a git repository
- 10430번
- Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encoding
- 항해99
- 코딩부트캠프후기
- 주니어개발자멘토링
- print sep
- 99클럽 #99일지 #코딩테스트 #개발자스터디 #항해 #til
- 개발자스터디
- MomentumParameters
- not a git repository
- Til
- 99일지
- 주니어개발자역량강화
- 개발자사이드프로젝트
- 파이썬
- 파이썬 클래스
- 항해플러스
- print("""
- 백준
- cp949
- 항해
- vscode cp949
- 코딩테스트
- EnvCommandError
Archives
- Today
- Total
선발대
[스파르타] 실전 머신러닝 적용 2주차 (완강) 본문
1. 수업 후기
- 강의 개수: 8개
- 총 강의시간: 1시간 5분
- 수업 목표:
- 1. 논리 회귀의 개념과 다양한 머신러닝 모델을 알아본다.
- 2. 머신러닝에서 쓰이는 전처리 기법들에 대해 배운다.
두 번째 머신러닝 수업! 이번에는 지난 시간에 이어 응용된 내용을 배웠다. 입력값과 출력 값이 다수인 경우 어떻게 해야 하는지를 알게 되었다. 처음부터 하나하나 내가 직접 망치로 배를 만드는 것이 아니라, 이미 만들어진 배를 타고 이동하는 것이다. 나는 그냥 빠르게 가기 위해 배를 탈지, 비행기를 탈지, 걸어갈지만 고민하면 되는 것이었다. 저번에 다른 강의에서 들었던 내용이 문득 생각났다.
실습과제는 여러 가지 요소가 있을 때 당뇨병 진단을 내리는 내용이었다. 처음 봤을 때는 이게 가능한가 싶었는데 앞서 배웠던 수업내용을 따라 하나하나 따라갔더니 금방 됐다. 결과가 바로바로 나오니까 재미있다. Pycharm만 써오다가 Colab 사용했더니 더 편한 것 같다. 다음 강의도 화이팅!
2. 수업내용 정리
2-1. 2주차 오늘 배울 것
더보기
더보기
01. 논리 회귀
- 논리 회귀(logistic regression): 입력값과 범주 사이의 관계를 구하는 것
- 선형 회귀로 풀 수 없는 것은 논리 회귀로 풀이.
- 1주차에는 regression, 2주차에는 classification을 논리 회귀로 풀이.
02. 전처리
- 전처리: 실제 업무에서 얻는 데이터는 오기입, 제각각인 단위 및 분포 등으로 정제작업이 이루어짐.
- 머신러닝에서 70~80%를 차지할 만큼 정확도에 영향.
2-2. 논리 회귀 (Logistic regression)
더보기
더보기

출처: https://ursobad.tistory.com/44

출처: https://ursobad.tistory.com/44

시그모이드 함수

01. 선형 회귀로 풀기 힘든 문제의 등장
- 대학교 시험 전날 공부시간에 따른 해당 과목의 이수 여부
- → 이수 여부를 0, 1이라는 이진 클래스(Binary class)로 구분함.
- 이런 경우는 선형회귀로 나타내면 아래처럼 그래프 이상하게 나옴.
- 따라서 이진 논리회귀(Binary logistic regression)으로 해결 가능.
- Logistic function(= Sigmoid function) 사용하면 아래처럼 그래프 생성됨.
- 로지스틱 함수는 입력값(x)는 어떤 값이든 받을 수 있지만, 출력결과(y)는 항상 0, 1 사이의 값이 됨.
- 실제 많은 자연, 사회현상에서는 특정 변수에 대한 확률값이 선형이 아닌 S커브를 따르는 경우가 다수임.
- 이런 S-커브를 함수로 표현해낸 것이 바로 로지스틱 함수(Logistic function)임.
- 딥러닝에서는 시그모이드 함수(Sigmoid function)이라고 부름.
- 시그모이드 함수는 x(입력)이 음수방향으로 갈수록 y(출력)이 0에 가까워지고, 반대는 1에 가까워짐.
- 즉, 시그모이드 함수 통과하면 0~1 사이 값이 나옴.
- 초록색 선을 threshold라고 부름. 여길 넘기면 1(통과) 아니면 0(탈락)으로 출력.
02. 가설과 손실 함수
- 논리회귀의 실질적인 계산은 선형회귀과 동일, 그러나 출력에 시그모이드 함수 붙여 0~1 사이 값을 가짐.
- 선형회귀 가설 H(x) = Wx + b 를 논리회귀의 시그모이드 함수에 넣어줌.
- x - 선형회귀 - 시그모이드 - H(x)
- 논리 회귀에서 손실함수는 복잡한 수식이 되지만, 수식보다는 개념을 이해하도록 해라.
- 확률분포그래프: 가로축을 라벨(클래스)로 표시하고, 세로축을 확률로 표시한 그래프.
- 확률분포그래프 차이를 감소시킬 때는 Crossentropy라는 함수를 이용함.
- → 임의의 입력값에 대해 우리가 원하는 확률분포그래프를 만들도록 학습시키는 손실함수.
- (선형회귀에서 정답 나타내는 점과 우리가 세운 가설직선과의 거리를 최소화하려고 했던 손실함수처럼)
- 처음 모델 학습시킬 때 파란색 그래프처럼 확률분포그래프가 나타남.
- Keras에서 이진논리회귀의 경우 binary_crossentropy 손실함수 사용함.
2-3. 다항 논리 회귀 (Multinomial logistic regression)
더보기
더보기
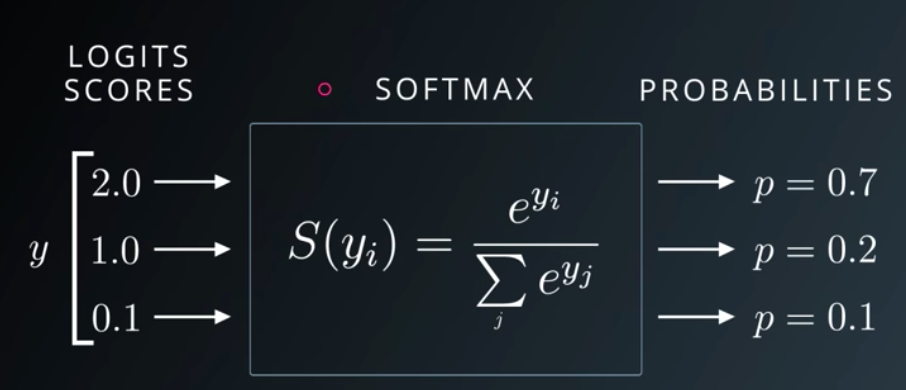
출처: https://www.tutorialexample.com/implement-softmax-function-without-underflow-and-overflow-deep-learning-tutorial/

출처: https://www.programmersought.com/article/62574848686/
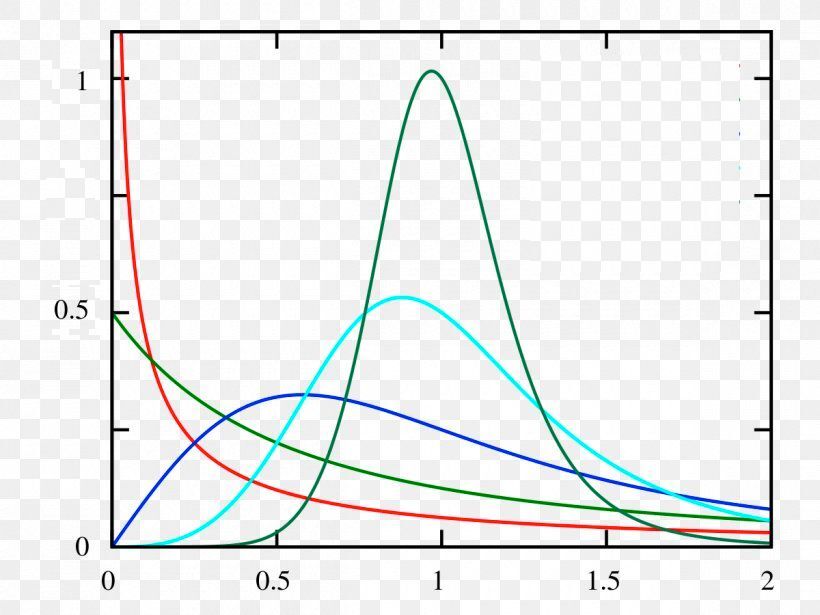
01. 다항 논리 회귀와 One-hot-encoding
- 대학교 시험전날 공부시간으로 해당 과목의 성적(A, B, C, D, F)을 예측하는 문제
- → 다중 논리회귀로 풀이함. 클래스를 5개로 나눔.
- 원핫 인코딩: 다항분류(Multi-label classification) 문제 풀 때 출력값의 형태를 깔끔하게 표현가능한 방법.
- 깔끔하다는 것은 컴퓨터 친화적이라는 의미.
- 다항 논리회귀도 다항분류에 해당하므로 원핫 인코딩 방법 사용함.
- ex) [1, 0, 0, 0, 0] [0, 1, 0, 0, 0] ... [0, 0, 0, 0, 1]
- 원핫 인코딩 생성방법:
- 1. 클래스(라벨)의 개수만큼 배열을 0으로 채움.
- 2. 각 클래스의 인덱스 위치를 정함.
- 3. 각 클래스에 해당하는 인덱스에 1을 넣음.
02. Softmax 함수와 손실함수
- 단항 논리회귀에서는 sigmoid function 사용.
- 다항 논리회귀에서는 sigmoid function 사용해서 0, 1로만 표현이 불가능함.
- Softmax 함수: 선형모델에서 나온 결과(Logit)을 전부 더하면 1이 되도록 만들어주는 함수.
- ∵ 예측의 결과를 확률(=Confidence)로 표현
- One-hot encoding 할 때도 라벨 값 전부 더하면 1(100%)이 된다
- Crossentropy 쓰는 건 동일하고(확률분포차이 최소화) 시그노이드 대신 소프트맥스 함수를 사용할 뿐임.
- 다항 논리회귀에서 softmax 함수를 통과한 결과값의 확률분포그래프가 위의 그래프라고 가정.
- 단항 논리회귀에서와 마찬가지로 가로축은 클래스(라벨), 세로축은 확률임.
- 역시 동일하게 확률분포 차이 계산할 때는 Crossentropy 함수 사용함.
- 우리가 학습시킬 방법: 데이터셋의 정답라벨과 우리가 예측한 라벨의 확률 분포 그래프를 구해서 Crossentropy로 두 확률 분포의 차이를 구한다음, 그 차이를 최소화하는 방향으로 학습시키기.
- Keras에서 다항 논리회귀의 경우 categorical_crossentropy 손실함수를 사용함.
2-4. 다양한 머신러닝 모델
더보기
더보기
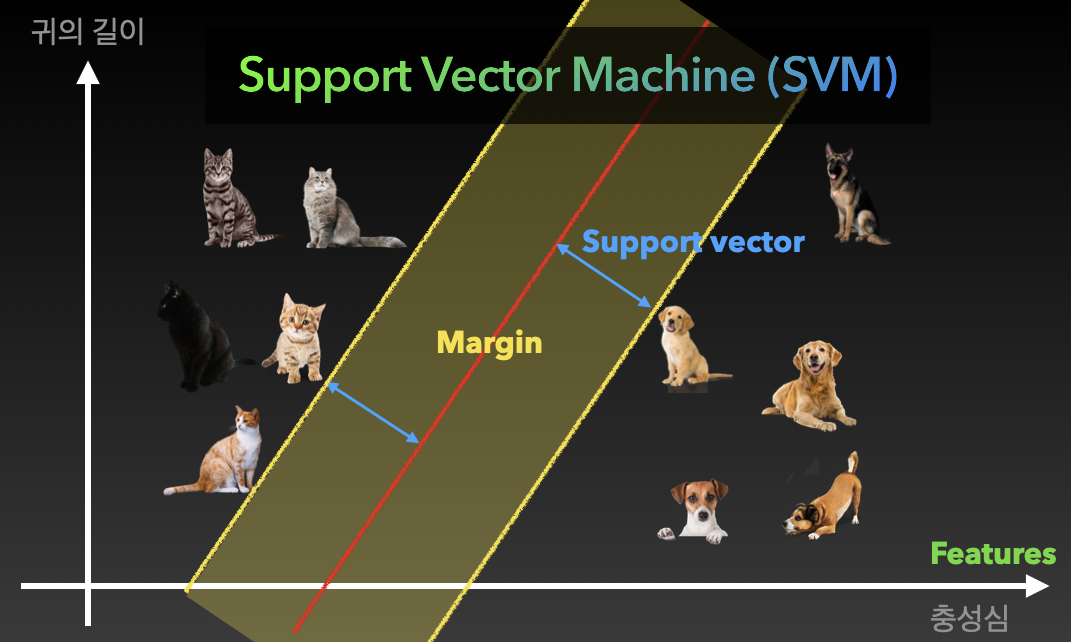



출처: http://www.joics.org/gallery/ics-1467.pdf
01. Support vector machine (SVM)
- 분류문제(Classification problem): 구분하는 문제를 푸는 것
- 분류기(Classifier): 분류문제를 푸는 모델
- 귀의 길이, 충성심에 따른 강아지, 고양이 구분하기
- → 강아지, 고양이 간의 거리가 최대가 되는 직선을 그리자
- Feature(특징): 각 그래프의 축
- Support vector: 각 강아지, 고양이와 빨간 벡터와의 거리
- Margin: support vector 사이의 거리. 가장 가까운 고양이, 강아지 사이의 거리.
- Margin이 넓어지도록 모델을 학습시켜 훌륭한 Support vector machine 만들 수 있음.
- 빨간색과 파란색 선의 사이가 넓어지도록(분류가 잘 되도록) 빨간색 선을 긋는다.
- Margin이 클수록 성능이 좋아짐. Support vector 가 멀도록.
- 주어진 feature으로 구분이 안된다면 새로운 feature을 추가해서 구분한다. 성능이 좋아짐.
- 분류문제의 기초 개념이며 딥러닝을 더 낮은 차원에서 이해할 수 있는 방법임.
02. 기타 머신러닝 모델 간단 소개
- k-Nearest neighbors(KNN): 비슷한 특성을 가진 개체끼리 군집화하는 알고리즘
- 일정 거리 안의 다른 개체들 수(k)를 보고 자신의 위치를 결정하게 하는 알고리즘
- 아래 사진의 경우에는 k=2 (가장 가까운 개체수) 를 보고 고양이라고 판단함.
- 직관적이고 간단하며 성능이 나쁘진 않음.
- Decision tree(의사결정나무): 스무고개 방식으로 예, 아니오를 반복하며 추론하는 방식. 성능 좋음.
- Random forest: 의사결정나무를 여러 개 합친 모양.
- 각각의 의사결정나무들이 결정하고 마지막에 투표(Majority voting)을 통해 최종 답을 결정함.
- 의사결정나무는 한 사람이 결정하는 것, 랜덤 포레스트는 자유민주주의 같은 것.
- 랜덤 포레스트도 성능이 좋은 것으로 유명함.
- 머신러닝은 몇 만차원이 되기도 하는데, 이렇게 차원을 낮춰서 생각하면 이해하기 쉽다.
- SVM이라고 검색하고 머신러닝 모델 사용하면 됨. 사용은 간단함. 모델마다 성능 차이가 있음.
- 각 상황에 따라 성능이 다르므로 적합한 모델을 찾아서 풀이하도록 해라.
2-5. 머신러닝에서의 전처리
더보기
더보기

출처: https://www.analyticsvidhya.com/blog/2020/04/feature-scaling-machine-learning-normalization-standardization/
01. 전처리 (Preprocessing)란?
- 전처리: 넓은 범위의 데이터 정제작업
- 필요없는 데이터 삭제하기, null값 있는 행 삭제하기, 정규화, 표준화 등의 많은 작업을 포함함.
- 머신러닝 실무에서 전처리가 80% 차지한다는 말이 있을 정도로 중요하고 시간이 오래 걸리며 실수도 잦음.
- 대표적인 전처리 작업에는 정규화와 표준화가 있음. 이것들이 필요한 이유는?
- ∵ 각 데이터 특성의 단위 및 범위가 다르기 때문에 직접적인 비교가 불가능함.
02. 정규화 (Normalization)
- 정규화: 데이터 범위를 0~1로 만든다. 같은 특성 데이터 중 가장 작은 값을 0, 가장 큰 값을 1로 만듦.
- 수식: X^1 = (X-X_최소) / (X_최대 - X_최소)
- 범위는 경우에 따라 달라질 수 있다. 핵심 개념은 데이터 간의 범위를 통일시킨다는 것.
- 거의 99%의 모델이 표준화, 정규화 중 정규화를 사용함.
03. 표준화 (Standardization)
- 표준화: 데이터 분포를 정규분포로 만든다. 데이터 평균을 0으로, 표준편차는 1로 만들어준다.
- 수식: X^1 = (X-X_평균) / X_표준편차
- 데이터 평균 0으로 맞춰주면 데이터 중심이 0에 맞춰짐(Zero-centered) + 표준편차 1로 = 정규화
- 표준화 시키면 일반적으로 학습속도(최저점 수렴속도)가 빠르고, Local minima에 빠질 가능성이 적음.
- 정규화와 표준화의 차이점: https://www.analyticsvidhya.com/blog/2020/04/feature-scaling-machine-learning-normalization-standardization/
2-6. 이진 논리회귀 실습
더보기
더보기
01. 타이타닉 생존자 예측하기
- 1. 데이터 다운받기
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'key' # key
!kaggle datasets download -d heptapod/titanic
!unzip titanic.zip # ! 붙여야 시스템 명령어 사용가능함.- 2. 필요한 패키지 임포트 하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler- 3. 데이터 로딩하기
df = pd.read_csv('train_and_test2.csv')- 4. 전처리하기
- 4-1. 사용할 컬럼 추출하기
df = pd.read_csv('train_and_test2.csv', usecols=[ # 사용할 컬럼
'Age', # 나이
'Fare', # 승차 요금
'Sex', # 성별
'sibsp', # 타이타닉에 탑승한 형제자매, 배우자의 수
'Parch', # 타이타니게 탑승한 부모, 자식의 수
'Pclass', # 티켓 등급 (1, 2, 3등석)
'Embarked', # 탑승국
'2urvived' # 생존 여부 (0: 사망, 1: 생존)
])
## 간단하게 데이터셋 미리보기
# 성별에 따른 생존자 수
sns.countplot(x='Sex', hue='2urvived', data=df)
# 생존여부 클래스의 개수 확인
sns.countplot(x=df['2urvived'])- 4-2. 비어있는 행 없애기
# 머신러닝 모델은 null 값이나 문자가 들어있을 경우(na) 오류 남.
# 1. 비어있는 값(null)이나 문자가 들어있는 값(na)이 있는지 확인하고,
print(df.isnull().sum())
# 2. 비어있는 값을 포함한 행을 제거함.
print(len(df)) # 1309
df = df.dropna()
print(len(df)) # 1307- 4-3. X, Y 데이터 분할하기
x_data = df.drop(columns=['2urvived'], axis=1) # 생존여부만 제외시키기
x_data = x_data.astype(np.float32) # 자료형: 32비트에서 소수점을 만들어줘야 TensorFlow에서 사용가능.
x_data.head(5) # 확인용
y_data = df[['2urvived']]
y_data = y_data.astype(np.float32)
y_data.head(5) # 확인용- 4-4. 표준화하기(평균 0, 표준편차 1로 맞추기)
- https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html
scaler = StandardScaler() # 정의하고
x_data_scaled = scaler.fit_transform(x_data) # 호출함. x데이터만 단위 다 다르니까 표준화.
print(x_data.values[0]) # 표준화 전 결과
print(x_data.scaled[0]) # 표준화 후 결과- 4-5. 학습/검증 데이터 분할하기
x_train, x_val, y_train, y_val = train_test_split(x_data, y_data, test_size=0.2, random_state=2021)
print(x_train.shape, x_val.shape) # 테스트 데이터, 검증 데이터
print(y_train.shape, y_val.shape)- 5. 모델 학습시키기
model = Sequential([ # 선형회귀 한번하고 논리회귀를 해라
Dense(1, activation='sigmoid') # 논리회귀에서는 sigmoid function 사용
])
# sigmoid functinon, binary_crossentropy 사용한다는 점만 다르다.
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.01), metrics=['acc'])
# 논리회귀에서는 loss 값만 보고 얼마나 잘 학습되었는지 감 잡기 힘듦.
# 그래서 metrics 등장. 앞으로 자주 사용하게 됨. 특히 분류문제 풀이 시에는 metrics 중 acc 자주 씀.
# 정확도를 0~1 사이에 나타내주는 지표. 1에 가까울수록 정확도가 100% 임.
# 좀 더 직관적으로 학습 경과를 알 수 있음.
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)
2-7. 다항 논리회귀 실습
더보기
더보기
01. 다항 논리회귀 (와인 종류 예측)
- 1. 데이터 다운받기
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'key' # key
!kaggle datasets download -d brynja/wineuci
!unzip wineuci.zip- 2. 필요한 패키지 임포트하기
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder # 다항논리회귀 할 때는 원핫인코더 사용- 3. 데이터 로딩하기
df = pd.read_csv('Wine.csv')
df.head(5) # 하면 헤더 내용이 없어서 수동으로 채워줘야 함. 아래 이어서 계속.- 4. 전처리하기
- 4-1. 헤더 정보 채워넣기
df = pd.read_csv('Wine.csv', names=[ # 헤더 내용 채워주기
'name' # 출력값(y): name(와인의 종류)
,'alcohol' # 입력값(x): name을 제외한 모든 칼럼
,'malicAcid'
,'ash'
,'ashalcalinity'
,'magnesium'
,'totalPhenols'
,'flavanoids'
,'nonFlavanoidPhenols'
,'proanthocyanins'
,'colorIntensity'
,'hue'
,'od280_od315'
,'proline'
])
df.head(5)
## 정답 라벨의 개수 확인
sns.countplot(x=df['name'])
## 전처리: 비어있는 행 확인
print(df.isnull().sum()) # 비어있는 행 없으므로 이 단계는 패스함- 4-2. X, Y 데이터 분할하기
x_data = df.drop(columns=['name'], axis=1) # name 칼럼 제외하고 전부 입력값임
x_data = x_data.astype(np.float32) # Keras 니까 자료형 변경
x_data.head(5) # 확인용
y_data = df[['name']] # y데이터는 name 만 있어야 함.
y_data = y_data.astype(np.float32)
y_data.head(5) # 확인용- 4-3. 표준화하기
scaler = StandardScaler()
x_data_scaled = scaler.fit_transform(x_data)
print(x_data.values[0])
print(x_data_scaled[0])- 4-4. One-hot 인코딩 하기
encoder = OneHotEncoder()
y_data_encoded = encoder.fit_transform(y_data).toarray()
print(y_data.values[0]) # 인코딩 하기 전에는 y값이 3종류 있었음
print(y_data_encoded[0])
# [1.] -> [1. 0. 0.]
# [2.] -> [0. 1. 0.]
# [3.] -> [0. 0. 1.]- 4-5. 학습/검증 데이터 분할하기
x_train, x_val, y_train, y_val = train_test_split(x_data_scaled, y_data_encoded, test_size=0.2, random_state=2021)
# spilt 할 때 x 데이터는 표준화된 것. y 데이터는 인코딩된 것.
print(x_train.shape, x_val.shape) # (142, 13) (36, 13) 13: feature 개수
print(y_train.shape, y_val.shape) # (142, 3) (36, 3) 3: 와인의 종류- 5. 모델 학습시키기
model = Sequential([
Dense(3, activation='softmax') # 출력 3개니까 dense 3, 다항 논리회귀니까 softmax
])
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.02), metrics=['acc'])
model.fit(
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)
2-8. 2주차 끝 & 숙제 설명
더보기
더보기
01. 이진 논리회귀 직접 해보기
- 연령, 혈압, 인슐린 수치 등을 통해 당뇨병을 진단해봅시다!
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'key' # key
!kaggle datasets download -d kandij/diabetes-dataset
!unzip diabetes-dataset.zip
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
df = pd.read_csv('diabetes2.csv') # df: data frame
# df.head(5) 한번 보고 표준화, 정규화 필요한지 확인하는게 중요함
x_data = df.drop(columns=['Outcome'], axis=1)
x_data = x_data.astype(np.float32)
y_data = df[['Outcome']]
y_data = y_data.astype(np.float32)
scaler = StandardScaler() # 표준화 시키기
x_data_scaled = scaler.fit_transform(x_data)
x_train, x_val, y_train, y_val = train_test_split(x_data_scaled, y_data, test_size=0.2, random_state=2021)
# print(x_train.shape, x_val.shape) 확인용 (614, 8) (154, 8)
# print(y_train.shape, y_val.shape) 확인용 (614, 1) (154, 1)
model = Sequential([
Dense(1, activation='sigmoid') # 이진 논리회귀이므로 출력은 1, sigmoid
])
# 이진 논리회귀이므로 binary_crossentropy 사용
model.compile(loss='binary_crossentropy', optimizer=Adam(lr=0.01), metrics=['acc'])
model.fit( # 학습 시작
x_train,
y_train,
validation_data=(x_val, y_val), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)'스파르타코딩클럽 > 강의 정리' 카테고리의 다른 글
| [스파르타] 실전 머신러닝 적용 4주차 (2) | 2022.01.11 |
|---|---|
| [스파르타] 실전 머신러닝 적용 3주차 (완강) (0) | 2022.01.11 |
| [스파르타] 실전 머신러닝 적용 1주차 (완강) (0) | 2022.01.05 |
| [스파르타] 협업을 위한 Git 활용 기초 3주차 (완강) (0) | 2022.01.05 |
| [스파르타] 협업을 위한 Git 활용 기초 2주차 (완강) (0) | 2021.12.29 |
'스파르타코딩클럽/강의 정리' Related Articles
more



Comments