
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
Tags
- 코딩부트캠프후기
- 항해
- 파이썬
- 파이썬 map 함수
- 99클럽 #99일지 #코딩테스트 #개발자스터디 #항해 #til
- 파이썬 클래스
- 10430번
- vscode cp949
- MomentumParameters
- 항해99
- print("""
- EnvCommandError
- 파이썬 int()
- 파이썬 |
- 백준
- Til
- 항해플러스
- cp949
- 파이썬 sep
- 99일지
- 99클럽
- print sep
- 개발자사이드프로젝트
- 주니어개발자멘토링
- fatal:not a git repository
- 주니어개발자역량강화
- not a git repository
- Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encoding
- 개발자스터디
- 코딩테스트
Archives
- Today
- Total
선발대
[스파르타] 실전 머신러닝 적용 3주차 (완강) 본문
1. 수업 후기
- 강의 개수: 8개
- 총 강의시간: 1시간 14분
- 수업 목표:
- 1. 딥러닝의 역사를 배운다.
- 2. 신경망을 만드는 데 필요한 각종 개념을 알아본다.
- 3. 신경망을 직접 디자인해본다.
2. 수업내용 정리
3-1. 3주차 오늘 배울 것
더보기
01. 딥러닝이란?
- 인공지능 → 머신러닝 → 딥러닝
- 선형회귀, 논리회귀는 모두 1차 함수로 문제를 풀었으나, 자연계에는 직선으로 풀 수 없는 문제가 많음.
- 복잡한 문제 풀이를 위해 선형회귀 반복했으나, 그렇다고 해서 비선형이 되는 것은 아님.
- 그래서 선형회귀 사이에 비선형의 무엇인가를 넣어야 한다고 생각해서 층을 여러 개 쌓기 시작함.
- 선형회귀 - 비선형 - 선형회귀가 이어지는 모델은 잘 동작했고, 층을 깊게(Deep) 쌓아서 딥러닝으로 부름.
- 딥러닝(Deep learning)의 다른 표현: Deep neural networks, Multilayer Perceptron(MLP)
02. 딥러닝의 주요 개념과 기법
- 신경망을 실제로 구성하는데 필요한 개념, 기법들에 대해 공부할 것임.
- 배치 사이즈와 에폭
- 활성화 함수
- 과적합과 과소적합
- 데이터 증강
- 드랍아웃
- 앙상블
- 학습률 조정
3-2. 딥러닝의 역사
더보기

Perceptron

OR, AND, XOR (XOR는 선형으로 나눌 수 없다)

Multilayer Perceptrons (MLP)

출처: https://developer.nvidia.com/blog/inference-next-step-gpu-accelerated-deep-learning/
01. XOR 문제
- AND, OR 문제 풀이하려면 직선 하나만 있으면 되는데, 이는 논리 회귀로 쉽게 만들 수 있었음.
- y = w0 + w1x1 + w2x2 → 이 수식을 그림을 나타낸 것을 Perceptron(퍼셉트론)으로 부름.
- w0, w1, w2 값만 잘 지정해주면 원하는 출력을 계산할 수 있기에, 생각하는 기계에 대한 기대치 높아짐.
- 그러나 XOR 문제는 풀지 못해서 Perceptron을 여러 개 붙인 Multilayer Perceptrons(MLP) 개념을 도입.
- Marvin Minsky 曰 '한 개의 perceptorn으로는 XOR 풀 수 없어서 MLP 사용해야 함.'
- 그러나 weight, bias 학습시키는 데 너무 많은 계산이 필요하므로 당시 기술로는 불가능하다고 주장함.
- 딥러닝(MLP, Neural networks)의 발전은 10~20년 정도 후퇴하게 됨.
02. Backpropagation (역전파)
- 딥러닝 침체기의 끝: 1974년 Paul Werbos(폴)의 박사논문
- 폴의 주장:
- 1. 우리는 W(weight), b(bias)을 이용해서 주어진 입력으로 출력을 만들 수 있음.
- 2. 그런데 MLP가 만들어낸 출력이 정답값과 다르면 W, b 조절 필요
- 3. 가장 좋은 조절방법: 출력에서 Error(오차) 발견해서 뒤(backward)에서 앞으로 점차 조절하는 방법.
- 반복적으로 계속 피드백 주면서 학습 시킨다. → 딥러닝의 개념
- 이 당시는 폴의 주장이 관심 못 받다가 1986년 Hinton 교수가 동일방법을 독자적으로 발표하며 알려짐.
- 이렇게 XOR 문제는 MLP를 풀 수 있어 해결되었고, 그 핵심방법은 역전파 알고리즘의 발견임.
3-3. Deep Neural Networks 구성 방법
더보기
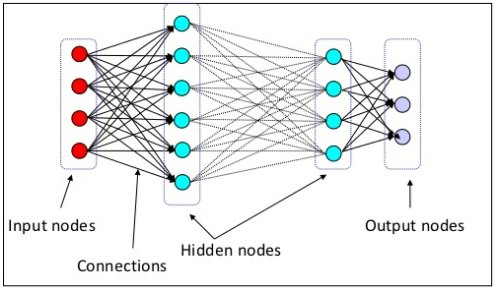
01. Layer(층) 쌓기
- 딥러닝 네트워크(MLP)는 여러 층을 쌓아 구성함. 이번 파트는 보편적인 층 쌓는 방법을 공부함.
- 딥러닝에서 네트워크의 구조는 크게 3가지로 구분됨.
- Input layer(입력층): 네트워크의 입력부분. 우리가 학습시키고 싶은 X 값.
- Output layer(출력층): 네트워크의 출력부분. 우리가 예측한 Y값.
- Hidden layer(은닉층): 입력층, 출력층을 제외한 중간층
- 각 층이 하나의 선형 회귀(Linear Regresssion)모델이라고 생각하면 됨.
- 풀어야 하는 문제에 따라 입력층, 출력층의 모양은 고정되어있음. 우리가 조절할 수 있는 건 은닉층.
- 은닉층은 완전연결계층(Fully connected layer = Dense layer)으로 구성됨.
- 기본적인 딥러닝에서는 보통 은닉층 중간 부분을 넓게 만드는 경우가 많음. 점차 늘렸다가 줄이기.
- ex) 입력층 노드개수(4) - 은닉층1(8) - 은닉층2(16) - 은닉층3(8) - 출력층 노드개수(3)
- 곧 배울 활성화함수의 위치도 중요한데, 보통 모든 은닉층 바로 뒤에 위치함.
- 딥러닝에서는 비선형함수를 활성화 함수라고 함.
- ex) 은닉층1 - 활성화함수 - 은닉층2 - 활성화함수 - 은닉층3 - 활성화함수
02. 네트워크의 Width(너비)와 Depth(깊이)
- Baseline(베이스라인 모델): 적당한 연산량과 정확도를 가진 완성된 딥러닝 모델을 보편적으로 지칭.
- 베이스라인 모델로 가장 간단하게 성능을 테스트하는 방법: 모델 너비, 깊이로 테스트하기
- 1. 네트워크 너비 늘리기: 은닉층의 노드 개수만 늘리기 ex) 은닉층1: 8*2 = 16, 은닉층2: 4*2 = 8
- 2. 네트워크 깊이 늘리기: 은닉층의 개수 늘리기 ex) 은닉층3 새롭게 추가
- 3. 네트워크 너비, 깊이 전부 늘리기
- 입력층, 출력층은 고정되어있음.
- 실무에서는 네트워크의 너비, 깊이를 변경하며 실험 많이 함. 시간도 많이 드는 노가다임.
- 그러나 다음 파트의 과적합, 과소적합 피하려면 꼭 필요한 노가다임.
3-4. 딥러닝의 주요 개념
더보기


출처: https://vitalflux.com/overfitting-underfitting-concepts-interview-questions/
01. Batch size, Epoch (배치 사이즈, 에폭)
- 머신러닝 때부터 쓰던 용어들이 딥러닝에도 이어져서 등장함.
- 천만 개 데이터셋을 한번에 메모리에 올리고 학습하려면, 천문학적 비용의 큰 용량 가진 메모리 필요.
- 배치(Batch): 데이터셋을 작은 단위로 쪼개서 학습시키는데, 쪼개는 단위를 의미함.
- 이터레이션(Iteration): 반복하는 과정. ex) 천만 개 데이터셋 천 개로 쪼개면 만 번 반복함.
- 에폭(Epoch): 전체 데이터셋을 한번 돌린 횟수.
- 배치 * 이터레이션(배치개수) = 전체 데이터셋 개수. 에폭은 배치 몇 개로 나눴는지 당연히 상관없음.
- 아래 그림에서는 100개 들어가서 forward 한 번하고, 다시 backpropagation 반복함.
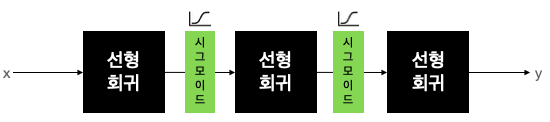
02. Activation functions (활성화 함수)
- MLP 연결구조가 여러 개의 뉴런이 연결된 모습과 비슷하다고 가정함.
- 활성화 함수: 전기 신호의 임계치(threshold)를 넘어야 다음 뉴런이 활성화한다고 해서 활성화함수.
- 보통 활성화 함수라고 하지 않고, activation 이라고 줄여서 말함.
- 활성화 함수는 비선형 함수여야 함. 대표적인 비선형 함수 예시: 시그모이드 함수
- 선형회귀 - 시그모이드 - 선형회귀 - 시그모이드 - 선형회귀의 반복.
- 활성화 함수의 종류:
- ReLu(렐루): 딥러닝에서 가장 보편적으로 사용. 학습이 빠르고 연산비용 적고, 구현 간단함.
- 렐루를 기본적으로 많이 쓰고 여러가지 활성화 함수 교체 노가다를 통해 최종 정확도 높임.
- 0보다 작으면 0, 0보다 크면 그대로 출력함. 간단. 성능도 잘 나옴.
- 이러한 노가다의 과정 → 모델튜닝
- 앞으로는 선형회귀 대신 딥러닝에서는 Dense layer가 밀집되어있다고 표현함.
- 또는 Fully Connected Layer, 줄여서 FCL로 부른다.
- FCL은 서로 전부 연결되어있음. FC레이어라고 많이 부름.
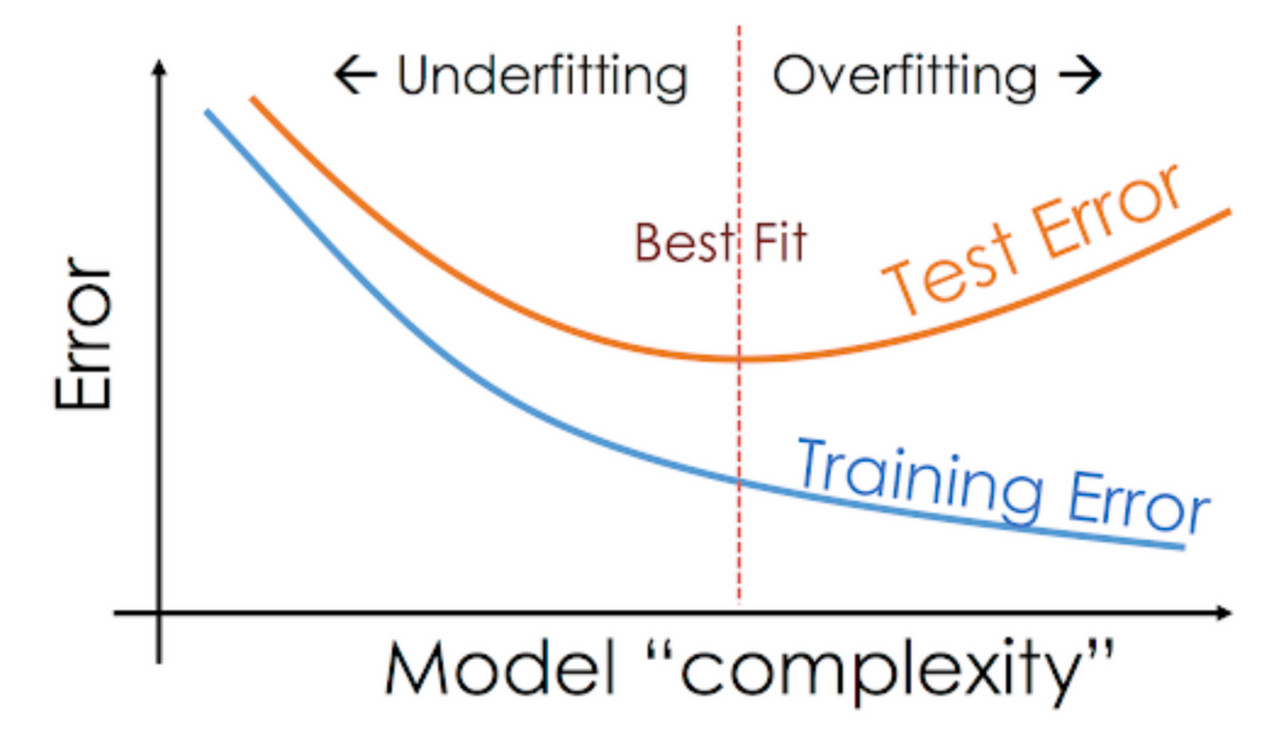
03. Overfitting, Underfitting (과적합, 과소적합)
- 과적합(Overfitting): 우리가 풀어야하는 문제의 난이도 < 모델 복잡도(Complexity)
- ex) 모의고사 정답번호 다 외워서 100점 받아도, 막상 수능은 계속 틀림.
- 과소적합(Underfitting): 문제의 난이도 > 모델 복잡도
- 수십 번의 튜닝과정을 거쳐 적당한 복잡도(최적합, Best fit)를 가진 모델을 찾아야 함.
- 보통 과소적합보다는 과적합 때문에 문제 발생.
- 대표적인 과적합 해결방법에는 데이터 더 모으기, Data augmenatinon, Dropout 등이 있음.
3-5. 딥러닝의 주요 스킬
더보기

출처:&amp;amp;nbsp;https://www.mygreatlearning.com/blog/understanding-data-augmentation/

출처:&amp;amp;amp;amp;nbsp;https://www.researchgate.net/figure/Dropout-Strategy-a-A-standard-neural-network-b-Applying-dropout-to-the-neural_fig3_340700034

출처: https://towardsdatascience.com/neural-networks-ensemble-33f33bea7df3

https://www.deeplearningwizard.com/deep_learning/boosting_models_pytorch/lr_scheduling/

출처:&amp;amp;amp;amp;nbsp;https://neurohive.io/en/popular-networks/resnet/
01. Data augmentation (데이터 증강기법)
- 과적합을 해결할 수 있는 가장 좋은 방법: 데이터 개수 늘리기
- 보통 실무에서 데이터 개수는 제한되어 있기 때문에, 데이터 보충하기 위해 데이터 증강기법 사용.
- 데이터 증강을 안하는 경우는 거의 없음. 성능도 좋음. 딥러닝이 일반화(Generalization)하도록.
- 데이터 증강기법: 이미 가진 기존의 데이터를 이용해서 데이터를 증강시키는 것.
- 이미지 처리 분야의 딥러닝에서 주로 사용함. → 이미지 한 장을 여러가지 방법으로 복사하는 것.
- 반드시 정해진 방법을 사용하는 것이 아니라, 새롭게 증강 방법을 만들어 낼 수 있음.
02. Dropout (드랍아웃)
- Dropout: 각 노드들이 이어진 선을 빼서 없애버리는 방식. 가장 간단히 과적합 해결 가능.
- 오른쪽 그림처럼 각 배치마다 랜덤한 노드를 끊음. 즉, 다음 노드로 전달할 때 출력을 0으로.
- 너무 많은 전문가(노드)들이 있으면 배가 산으로 감. 적당히 전문가 추려서 반복적으로 결과내기.
- Dropout은 과적합 발생시 생각보다 좋은 효과 나타남. 사용하기도 간단해서 나중에 이용 추천!
03. Ensemble (앙상블)
- 앙상블: 여러 개 딥러닝 모델 만들어 각각 학습시키고 각 모델 출력을 기반으로 투표하는 방법.
- 충분한 컴퓨팅 파워만 있다면 가장 시도해보기 쉬운 방법.
- 앞에서의 랜덤 포레스트 기법과 비슷함.
- 여러 개 모델 출력 중 어떻게 최종 출력을 결정하나?
- 다수결로 투표하기, 평균값 구하기, 마지막에 결정하는 레이어 붙이기 등의 다양한 방법으로 응용.
- 앙상블 사용하면 최소 2% 이상의 성능 효과를 볼 수 있다고 알려짐.
04. Learning rate decay (Learning rate schedules)
- 실무에서 자주 쓰는 기법. Local minimum에 빠르게 도달하고 싶을 때 사용함.
- 실제로 Global minimum에 도달하는 건 힘들다. 정답값이니까.
- 보통은 로컬에 많이 도달함. 그래서 로컬 미니멈이라고 말하는 것이 정확한 표현임.
- Learning rate 줄어들때마다 Error 값도 한 번씩 큰 폭으로 줄어드는 모습.
- 러닝 레이트는 처음에는 큰 폭으로 가다가 점차 줄어든다.
- 오버슈팅을 막는 좋은 방법임.
- Keras에서 학습중 Learning rate를 조절하는 방법:
- tf.keras.callbacks.LearningRateScheduler(), tf.keras.callbacks.ReduceLROnPlateau()
3-6. XOR 실습
더보기

model.summary() : 모델 개요(구조)를 확인할 수 있음
01. 딥러닝으로 XOR 문제 풀어보기
- 1. 필요한 패키지 임포트하기
import numpy as np
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from tensorflow.keras.optimizers import Adam, SGD- 2. XOR 데이터셋 만들기
x_data = np.array([[0, 0], [0, 1], [1, 0], [1, 1]], dtype=np.float32) # Keras에서 값을 받으므로 자료형 변경
y_data = np.array([[0], [1], [1], [0]], dtype=np.float32)- 3. 이진논리회귀로 풀어보기
model = Sequential([
Dense(1, activation='sigmoid') # 이렇게 하면 안 풀릴 것임. 한번 확인해보자.
])
# 이진 논리회귀니까 binary_crossentropy 사용함.
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
model.fit(x_data, y_data, epochs=1000, verbose=0)
# verbose 가 0이면 출력 X, 1이면 출력해라.
y_pred = model.predict(x_data) # 0.5에 가깝게 출력된다 -> 실패!- 4. 딥러닝(MLP)로 풀어보기
model = Sequential([
Dense(8, activation='relu'), # 히든 레이어 FCL, Dense layer, 노드 8개
Dense(1, activation='sigmoid'), # 출력 y값은 1개
])
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
model.fit(x_data, y_data, epochs=1000, verbose=0)
y_pred = model.predict(x_data) # 0 1 1 0 에 가까운 값이 나옴- 5. Keras Functional API 써보기
# 지금까진 Keras의 Sequential 클래스를 사용해서 Sequential API 사용했음.
# 순차적인 모델 설계에는 편리한 API지만 복잡한 네트워크 설계할 때는 한계가 있음.
# 따라서 실무에서는 Functional API를 주로 사용함. 시퀀셜은 거의 안 씀.
# 약간 복잡해지는 대신에 좀 더 우리 입맛에 맞는 네트워크를 만들 수 있음.
import numpy as np
from tensorflow.keras.models import Sequential, Model # Model 클래스 등장
from tensorflow.keras.layers import Dense, Input # Input 도 부르기
from tensorflow.keras.optimizers import Adam, SGD
input = Input(shape=(2,)) # input 레이어 크기 지정. XOR은 입력값(노드)이 2개임.
hidden = Dense(8, activation='relu')(input) # input 레이어를 넣어줌
output = Dense(1, activation='sigmoid')(hidden) # 다음 레이어로 순차적으로 넣어줌
model = Model(inputs=input, outputs=output) # 복수형으로 되어있음. 입, 출력값 개수 상관없도록.
model.compile(loss='binary_crossentropy', optimizer=SGD(lr=0.1))
model.summary()
# Functional API 사용하면 model.summary() 사용해서 구조 확인하기 쉽다는 장점이 있음.
model.fit(x_data, y_data, epochs=1000, verbose=0)
y_pred = model.predict(x_data)
print(y_pred) # 0 1 1 0 에 가까운 값이 나옴
- Output Shape: (None, 2) None은 배치 사이즈임. 우리가 설정 가능함. 노드 출력이 2개임.
- 선형회귀를 TensorFlow로 구현할 때도 None 사용했었음.
- Non-trainable params: 트레이닝 안하는 파라미터의 개수.
- 보통 Dropout이나 normalizatino layer들이 트레이닝을 안해서 여기에 들어감.
- 파라미터: 학습된 파라미터들
3-7. 딥러닝 실습
더보기


01. Sign Language MNIST (수화 알파벳) 실습
- 지금까지는 CPU 사용했는데, GPU 사용하면 딥러닝 연산속도 대폭 향상 가능.
- 1. [런타임Runtime] - [런타임 유형 변경 Change runtime type] - GPU 선택해서 연산속도 늘리기
- 2. 데이터셋 다운로드
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'key' # key
!kaggle datasets download -d datamunge/sign-language-mnist
!unzip sign-language-mnist.zip- 3. 필요한 패키지 임포트하기
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder- 4. 데이터셋 로드하기
train_df = pd.read_csv('sign_mnist_train.csv')
test_df = pd.read_csv('sign_mnist_test.csv')
# train_df.head() 확인용, 가로 및 세로가 28픽셀로 구성됨. 컬럼은 784개. A부터 0으로 카운트함.
# test_df.head()- 5. 라벨 분포 확인하기
- J(9) or Z(25)는 동작이 들어가서 제외함. 따라서 총 24개의 라벨.
plt.figure(figsize=(16, 10))
sns.countplot(train_df['label'])
plt.show()- 6. 전처리하기
- 6-1. 입력과 출력 나누기
train_df = train_df.astype(np.float32)
x_train = train_df.drop(columns=['label'], axis=1).values # .values는 np.array로 변환하겠다
y_train = train_df[['label']].values
test_df = test_df.astype(np.float32)
x_test = test_df.drop(columns=['label'], axis=1).values
y_test = test_df[['label']].values
# print(x_train.shape, y_train.shape)
# print(x_test.shape, y_test.shape)- 6-2. 데이터 미리보기
index = 1
plt.title(str(y_train[index]))
# 픽셀이 1차원으로 주르륵 있으니까 이걸 reshape 해서 2차원으로 변경해준다.
plt.imshow(x_train[index].reshape((28, 28)), cmap='gray')
plt.show()- 6-3. One-shot 인코딩하기
encoder = OneHotEncoder()
y_train = encoder.fit_transform(y_train).toarray() # 라벨값만 인코딩 해주고 array 형태로 변경.
y_test = encoder.fit_transform(y_test).toarray()
# print(y_train.shape)- 6-4. 일반화하기
- 이미지 데이터는 픽셀이 0~255 사이의 정수(unsigned integer 8bit = uinit8)로 되어있음.
- 이것을 255로 나누어 0~1 사이의 소수점 데이터(floating point 32bit = float32)로 바꾸고 일반화.
x_train = x_train / 255.
x_test = x_test / 255.
# 이 블럭 2번 실행시키면 안되고 한 번만 실행시켜라- 7. 네트워크 구성하기
input = Input(shape=(784,))
hidden = Dense(1024, activation='relu')(input)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dense(256, activation='relu')(hidden)
output = Dense(24, activation='softmax')(hidden) # 다항 논리회귀
model = Model(inputs=input, outputs=output)
# 다항 논리회귀
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
# model.summary()- 8. 모델 학습시키기
history = model.fit(
x_train,
y_train,
validation_data=(x_test, y_test), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)- 9. 학습 결과 그래프
plt.figure(figsize=(16, 10))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.figure(figsize=(16, 10))
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
- 가로축: 에폭 수, 세로축: Loss (트레이닝: 파란색, 유효: 주황색)
- 가로축: 에폭수, 세로축: acc
3-8. 3주차 끝 & 숙제 설명
더보기
01. 숫자 MNIST
- 머신러닝에서 가장 유명한 데이터셋 중 하나인 MNIST DB 직접 분석해보기
- MNIST 데이터베이스: 손으로 쓴 0~9까지의 숫자 이미지 모음
# 데이터셋 다운로드
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'key' # key
!kaggle datasets download -d oddrationale/mnist-in-csv
!unzip mnist-in-csv.zip
# 패키지 로드
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense
from tensorflow.keras.optimizers import Adam, SGD
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder
# 데이터셋 로드
train_df = pd.read_csv('mnist_train.csv')
test_df = pd.read_csv('mnist_test.csv')
# trian_df.head() # 맨 앞 컬럼이 label이 됨. 0~9까지의 수.
# gray scale은 가장자리 픽셀값이 다 검은색일 때 0이 된다.
# test_df.head()
# 라벨 분포
plt.figure(figsize=(16, 10))
sns.countplot(train_df['label']) # 분포 볼 때 사용
plt.show()
# 전처리: 입력과 출력 나누기
train_df = train_df.astype(np.float32)
x_train = train_df.drop(columns=['label'], axis=1).values
y_train= train_df[['label']].values
test_df = test_df.astype(np.float32) # 소수점으로 변경
x_test = test_df.drop(columns=['label'], axis=1).values # 라벨 빼고 np.array로
y_test = test_df[['label']].values # 라벨만 np.array로
# print(x_train.shape, y_train.shape) # (60000, 784) (60000, 1) 데이터 크기는 784개, 출력은 1 -> 인코딩으로 10개로 만듦
# print(x_test.shape, y_test.shape) # (10000, 784) (10000, 1) 이미지 개수는 10000개
# 데이터셋 미리보기
index = 1
plt.title(str(y_train[index]))
plt.imshow(x_train[index].reshape((28, 28)), cmap='gray') # 1차원 -> 2차원
plt.show()
# One-hot encoding
encoder = OneHotEncoder()
y_train = encoder.fit_transform(y_train).toarray() # y값만 인코딩하기
y_test = encoder.fit_transform(y_test).toarray()
# print(y_train.shape) # (60000, 10) -> 1에서 10으로 인코딩
# 일반화: 0~1까지의 소수점으로
x_train = x_train / 255.
x_test = x_test / 255.
# 네트워크 구성
input = Input(shape=(784,))
hidden = Dense(1024, activation='relu')(input)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dense(256, activation='relu')(hidden)
output = Dense(10, activation='softmax')(hidden) # 아웃풋 개수 설정해주기, 다항논리회귀 softmax
model = Model(inputs=input, outputs=output)
# 다항논리회귀 categorical_crossentropy
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()
# 학습
history = model.fit(
x_train,
y_train,
validation_data=(x_test, y_test), # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)
# 학습 결과 그래프
plt.figure(figsize=(16, 10)) # 오버피팅 되고 있다는 것을 알 수 있음
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.figure(figsize=(16, 10))
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])'스파르타코딩클럽 > 강의 정리' 카테고리의 다른 글
| [스파르타] Django 기초반 1주차 (완강) (0) | 2022.01.19 |
|---|---|
| [스파르타] 실전 머신러닝 적용 4주차 (2) | 2022.01.11 |
| [스파르타] 실전 머신러닝 적용 2주차 (완강) (0) | 2022.01.11 |
| [스파르타] 실전 머신러닝 적용 1주차 (완강) (0) | 2022.01.05 |
| [스파르타] 협업을 위한 Git 활용 기초 3주차 (완강) (0) | 2022.01.05 |
'스파르타코딩클럽/강의 정리' Related Articles
more



Comments