
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 99클럽
- Fatal Python error: init_fs_encoding: failed to get the Python codec of the filesystem encoding
- 99클럽 #99일지 #코딩테스트 #개발자스터디 #항해 #til
- 파이썬
- 항해
- 파이썬 |
- 항해99
- 파이썬 sep
- vscode cp949
- not a git repository
- 주니어개발자멘토링
- EnvCommandError
- 코딩테스트
- 개발자사이드프로젝트
- 10430번
- 99일지
- 개발자스터디
- 항해플러스
- print("""
- Til
- 주니어개발자역량강화
- 파이썬 클래스
- fatal:not a git repository
- print sep
- 파이썬 int()
- 파이썬 map 함수
- 코딩부트캠프후기
- cp949
- MomentumParameters
- 백준
Archives
- Today
- Total
선발대
[스파르타] 실전 머신러닝 적용 4주차 본문
1. 수업 후기
- 강의 개수: 10개
- 총 강의시간: 1시간 21분
- 수업 목표:
- 1. 다양한 딥러닝 신경망 구조에 대해 알아본다
- 2. 전이 학습에 대해 배운다.
- 3. CNN과 전이학습을 직접 적용해본다.
안녕하슈크림
2. 수업내용 정리
4-1. 4주차 오늘 배울 것
더보기

출처: https://www.cnblogs.com/wangxiaocvpr/p/6247424.html
01. 다양한 신경망 구조
- 신경망 구성방법에는 여러 가지가 있음.
- 가장 많이 쓰이는 방법들: 합성곱 신경망(CNN), 순환 신경망(RNN), 생성적 적대 신경망(GAN)
- 우리가 3주차에 배웠던 DFF 도 아래에 나와있음.
02. 전이학습
- 전이학습: 이미 학습된 모델을 비슷한 문제 풀 때 다시 사용하는 것
- 더 적은 데이터로 더 빠르고 정확하게 학습시킬 수 있어 실무에서도 많이 사용함.
4-2. Convolutional Neural Networks (합성곱 신경망)
더보기

출처: https://ce-notepad.tistory.com/14
출처: https://towardsdatascience.com/intuitively-understanding-convolutions-for-deep-learning-1f6f42faee1
출처: https://stackoverflow.com/questions/42883547/intuitive-understanding-of-1d-2d-and-3d-convolutions-in-convolutional-neural-n
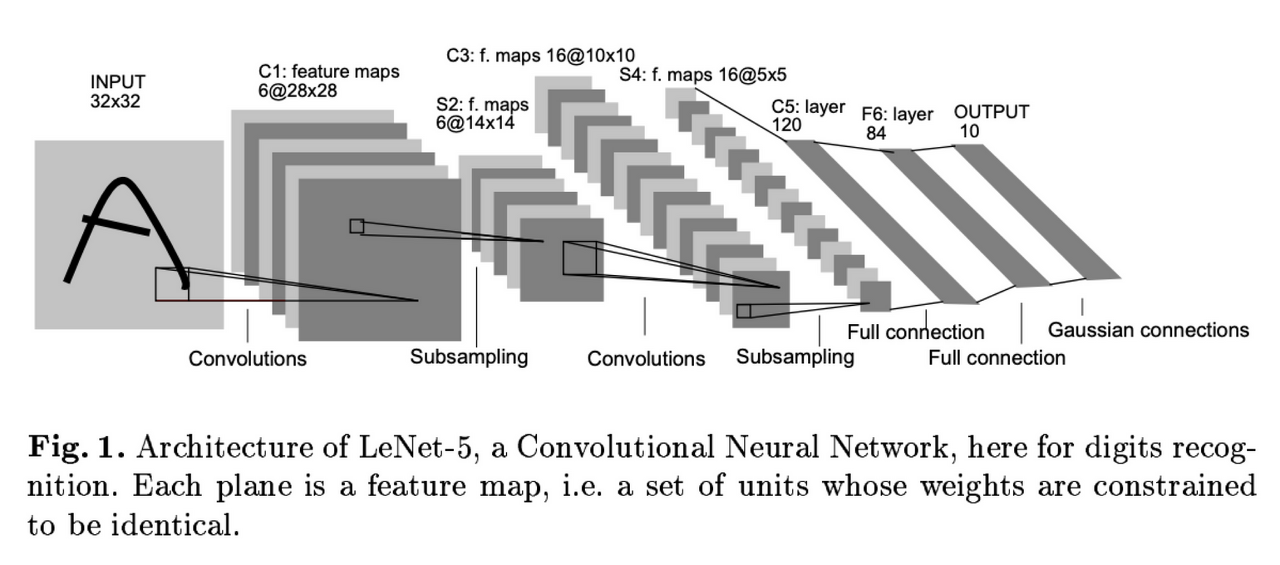
01. 합성곱과 합성곱 신경망
- 합성곱(Convolution): 입력데이터와 필터의 각각 요소를 서로 곱한 후 더하면 출력값이 됨.
- 예전부터 컴퓨터 비전(Computer Vision, CV) 분야에서 많이 사용하는 이미지 처리방식.
- 1998년 Yann LeCun 교수님이 합성곱 신경망(CNN) 명칭 발표.
- CNN은 이미지 처리에서 엄청난 성능을 보이며 딥러닝의 전성기가 시작됨.
- 얼굴인식, 사물인식 등에 널리 사용, 현재도 이미지 처리에서 가장 보편적으로 사용되는 네트워크 구조.
- 입력값을 넣고 합성곱 연산을 하면 특성맵(Feature map)을 뽑아낼 수 있음.
- 그림의 특성을 잘 반영한 피처맵을 뽑아내고 Subsampling(차원축소, 핵심만 뽑기) 또 합성곱...
- Full connection(Keras에서는 Dense layer, FCL)로 다시 연결해서 Output 뽑아내면 성능 좋음.
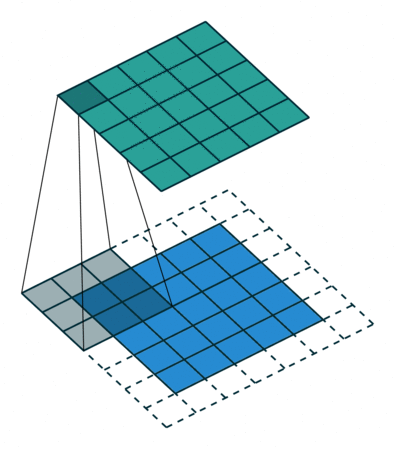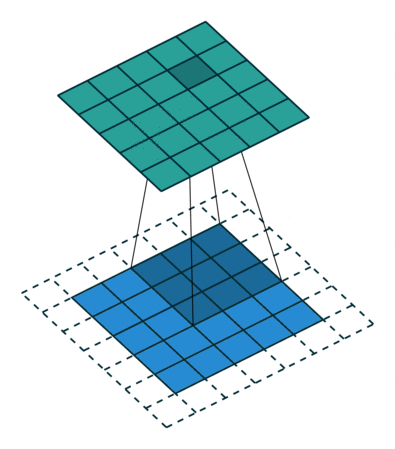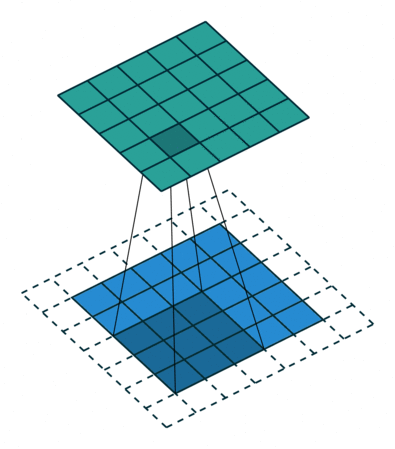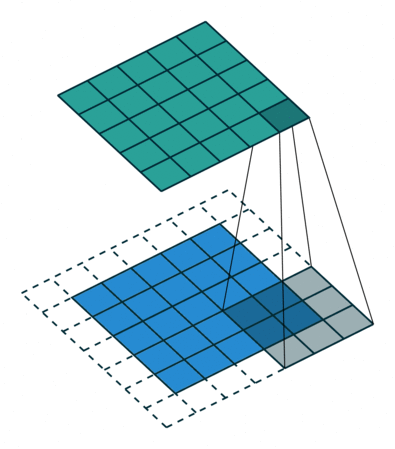
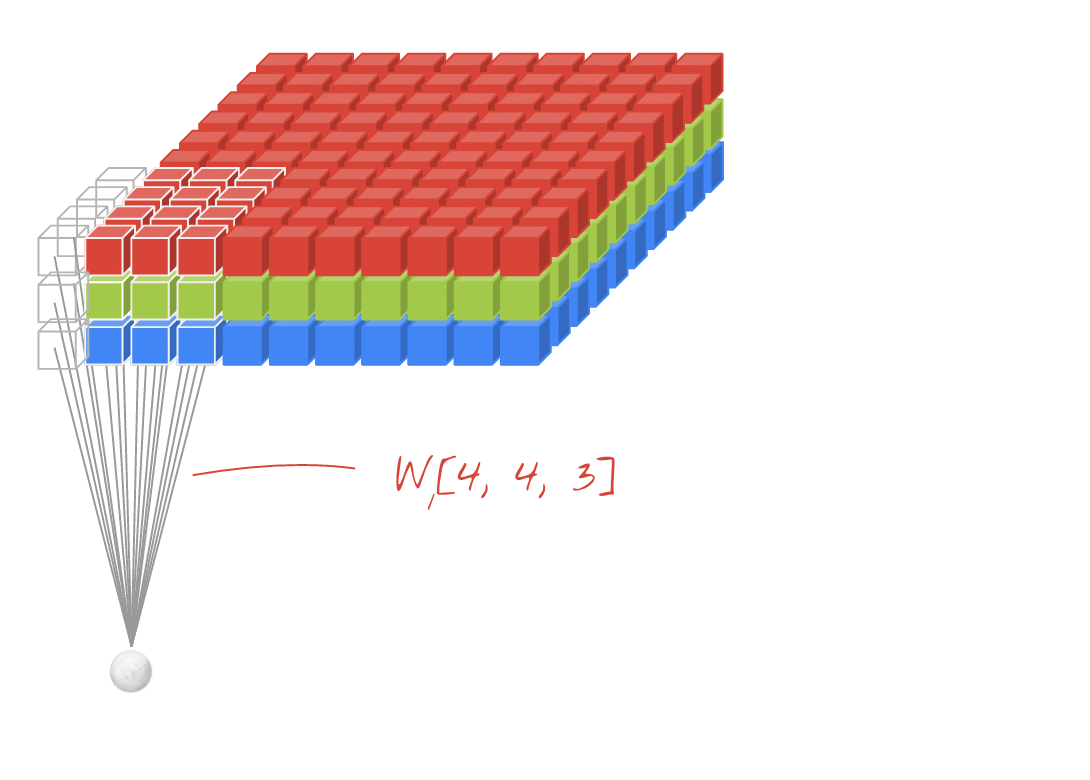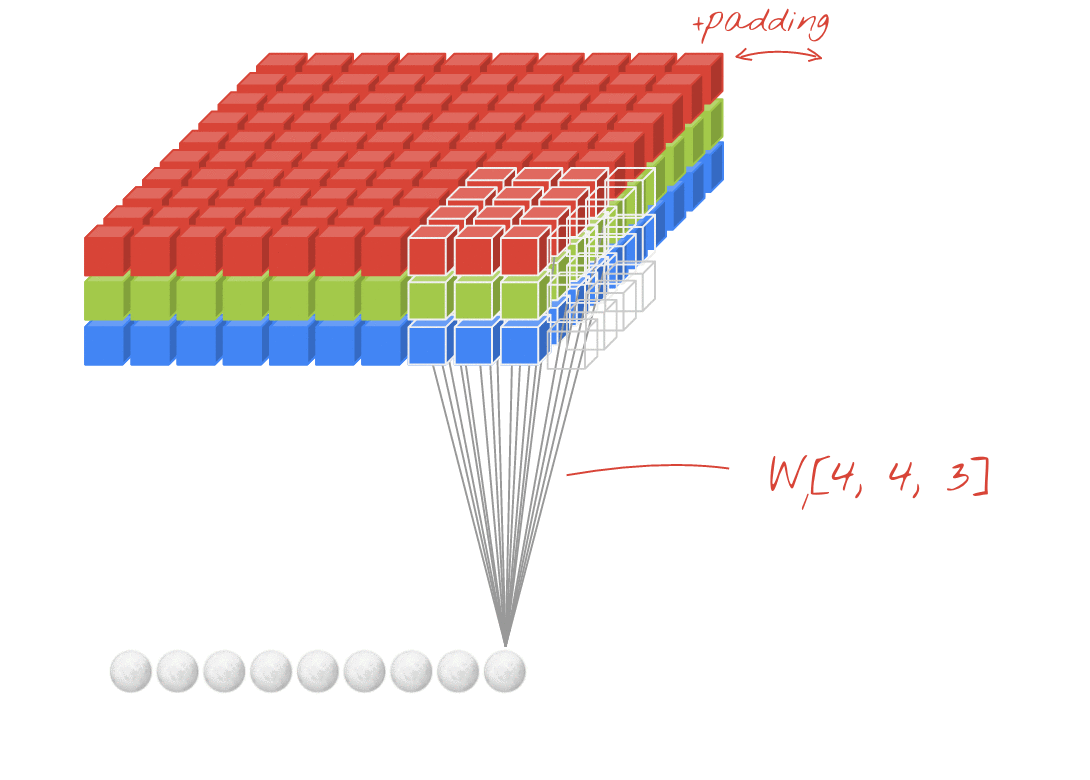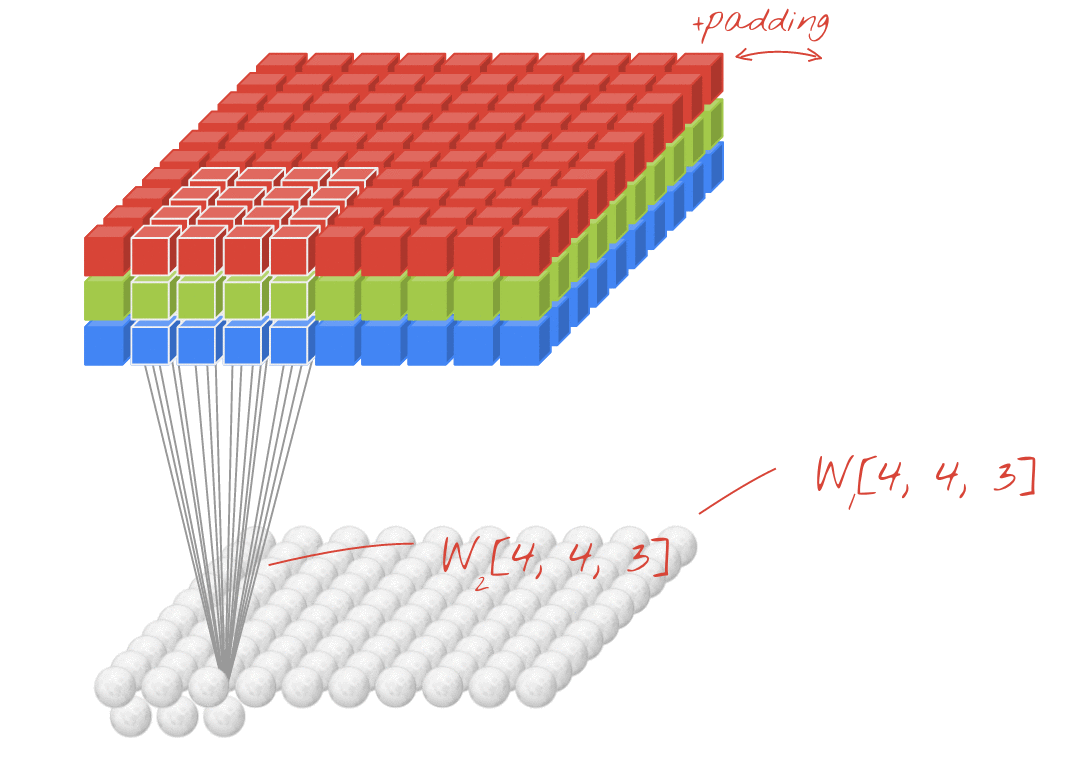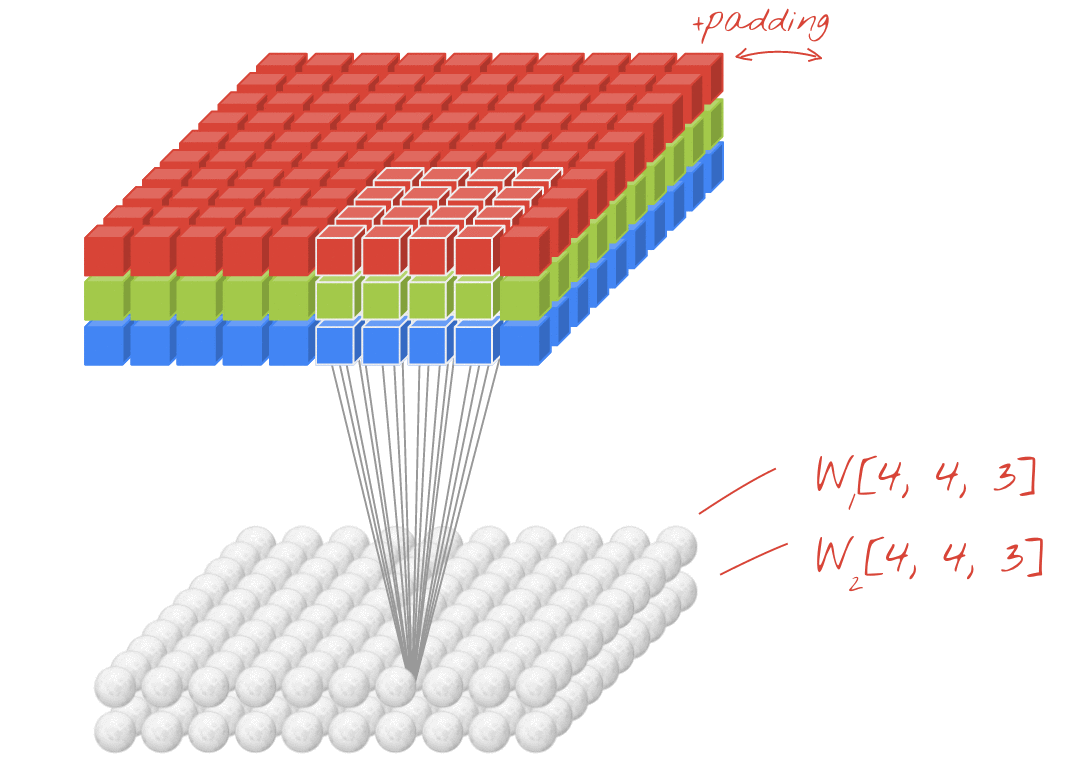
02. Filter, Strides and Padding
- 합성곱 신경망에서 가장 중요한 합성곱 계층(Convolution layer)에 대해 알아보기.
- 입력 크기: 5X5, 필터 크기: 3X3 → 특성맵(Feature map) 크기: 3X3 뽑아낼 수 있음.
- 필터(Filter 또는 Kernel)를 한 칸씩 오른쪽으로 움직이며 합성곱 연산을 함.
- 스트라이드(Stride): 이동하는 간격
- 합성곱 연산 특성상 필터 크기에 따라 출력값인 특성맵 크기가 작아짐.
- 이런 현상을 방지하기 위해, 패딩(Padding 또는 Margin)을 줘서 스트라이드 1일때 크기 동일하게 만듦.
- 여러 개의 필터를 이용해서 합성곱 신경망의 성능 높일 수 있음.
- 그러면 이미지는 3차원(가로, 세로, 패널)이므로 여러 층으로 구성됨.
- 입력 이미지 크기: (10, 10, 3) # 보통 컬러이미지는 RGB
- 필터의 크기: (4, 4, 3)
- 필터의 개수: 2 -> 두께도 2개로 출력됨
- 출력 특성 맵의 크기: (10, 10, 2) -> 패딩 줘서 입출력 크기 동일함.
4-3. CNN의 구성
더보기
https://teknoloji.org/cnn-convolutional-neural-networks-nedir/
출처: https://developers.google.com/machine-learning/practica/image-classification/convolutional-neural-networks

출처: https://www.kaggle.com/questions-and-answers/59502
https://teknoloji.org/cnn-convolutional-neural-networks-nedir/

출처: https://www.superdatascience.com/blogs/convolutional-neural-networks-cnn-step-3-flattening

출처: https://arxiv.org/abs/1612.04402v1

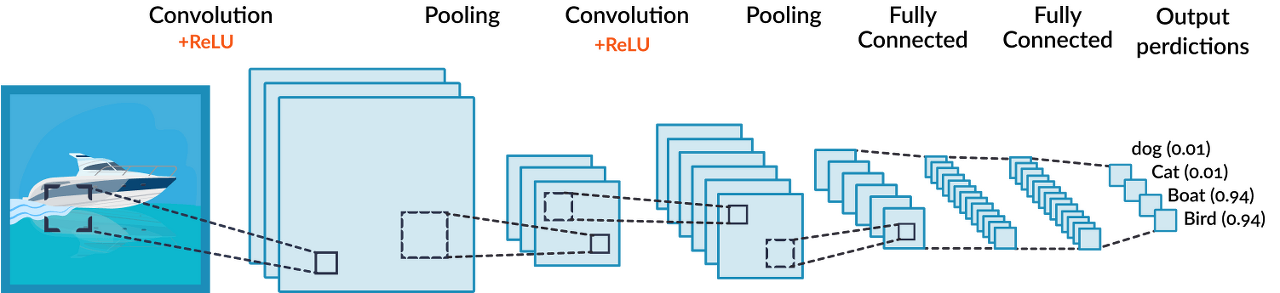
01. CNN의 구성
- 합성곱 신경망은 합성곱 계층(Convolution layer)과 완전연결 계층(Dense layer)을 함께 사용함.
- 합성곱 계층 + 활성화 함수 + 풀링 반복하며 작아지고 핵심적인 특성 뽑아냄.
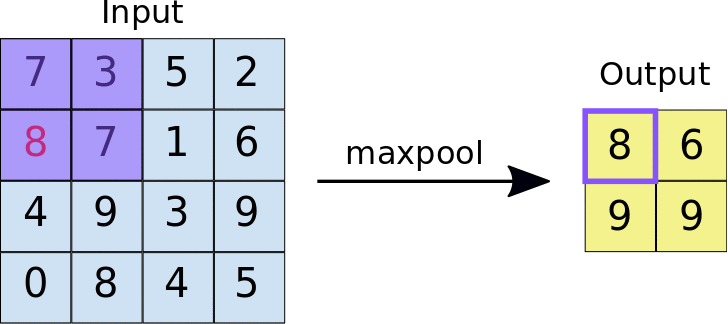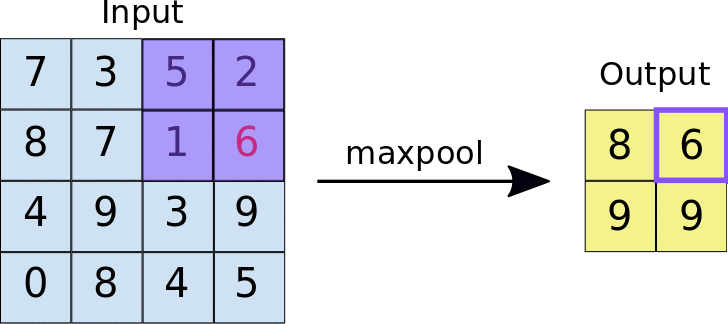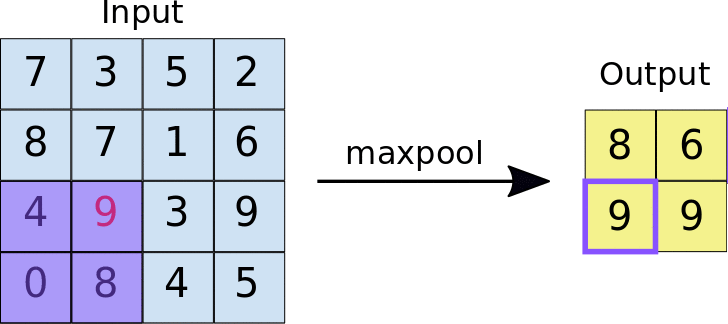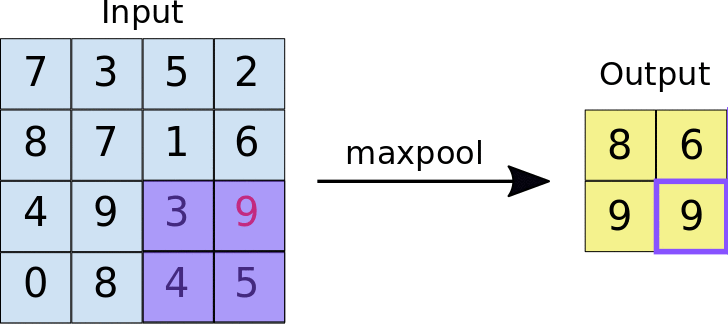
- 풀링 계층(Pooling layer): 특성 맵의 중요부분을 추출하여 저장하는 역할을 함.
- Subsampling 작업임. 차원을 축소하는 작업. 차원 축소 자체가 중요부분 추출한다는 의미.
- 마지막 풀링이 끝나면 , 2차원인 풀링을 1차원으로 펼쳐서 FCL(DL)에 연결함.
- 연결작업도 반복해서 나중에 우리 정답값을 예측하게 하는 출력을 나타나게 함.
- <2X2 크기의 특성맵에서 스트라이드가 2일 때>
- Max pooling: 특성맵에서 가장 큰 값들을 추출하는 방식
- Average pooling: 특성맵에서 평균값을 추출하는 방식
- 두 번째 풀링계층 지나면 완전연결계층과 연결되어야 함.
- 그러나 풀링 통과한 특성맵은 2차원이고, 완전연결계층은 1차원이므로 연산 불가능함.
- ∴ 평탄화계층(Flatten layer)을 사용해서 2차원을 1차원으로 펼치는 작업 해야 함.
- 평탄화 계층 통과하면 완전연결계층에서 행렬 곱셈을 할 수 있게 됨.
- 마찬가지로 완전연결계층 + 활성화 함수 반복을 통해 점차 노드의 개수 축소시킴.
- 마지막에는 Softmax 활성화 함수를 통과하고 출력층으로 결과를 출력함.
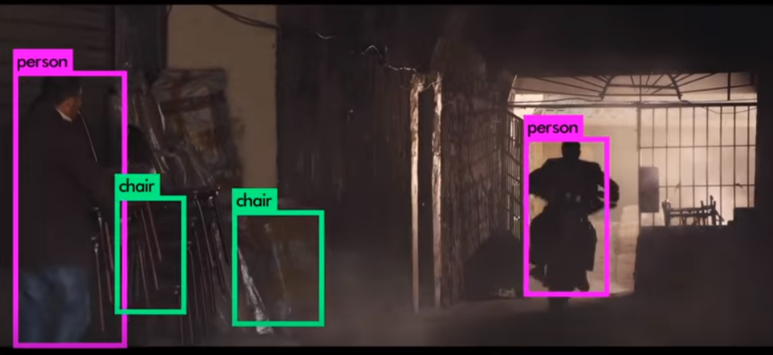
02. CNN의 활용 예
- CNN은 다양한 컴퓨터 비전 분야에서 사용됨.
- 물체 인식(Object Detection): 사진 이미지에서 물체를 정확히 인식하는 기술. 컴퓨터 비전 핵심기능.
- YOLO(You Only Look Once): 현재 V5까지 나옴. 정확도와 속도가 빠르다는 강점.
- 이미지 분할(Segmentatino): 각각의 오브젝트에 속한 픽셀들을 분리하는 것을 의미함. 윤곽선.
- 나누는 기준이 세부적일수록 정교화된 성능을 가져야 하며, 처리속도 또한 고려해야 함.
- 활용 예시:
- 자율주행 물체인식(인식률 및 정확도 100% 필요, CV 활용기술 중 상용화가 가장 빠른 분야임)
- 자세인식(Pose Detection, 저스트 댄스 게임도 이것을 이용함)
- 화질개선(Super Resolution, 이미지에서 각 feature 인식한 후 고화질의 영상으로 추론함)
- Style Transfer(이미지에 다양한 화풍 입히기)
- 사진 색 복원(Colorization)
4-4. 다양한 CNN 종류
더보기

출처:&amp;amp;nbsp;https://www.researchgate.net/figure/Results-shown-in-Canziani-et-al2016-that-compare-model-accuracy-vs-operation-count_fig5_339199431
출처: https://tariq-hasan.github.io/concepts/computer-vision-cnn-architectures/

출처: https://neurohive.io/en/popular-networks/resnet/
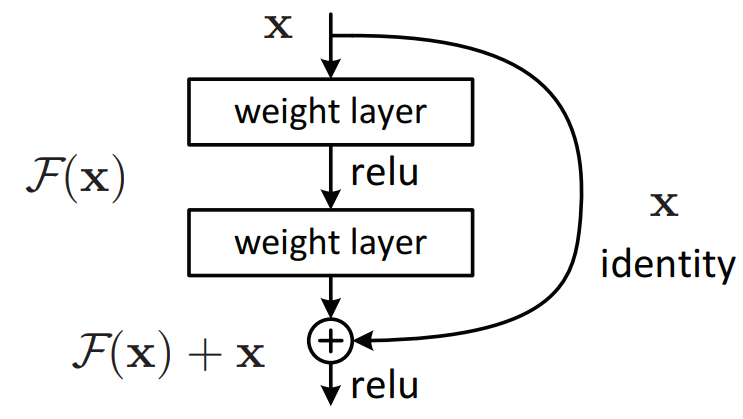
출처: https://neurohive.io/en/popular-networks/resnet/
01. 다양한 CNN의 종류 (= 네트워크의 종류)
- 가로축: 연산수, 세로축: 정확도
- 연산량이 많다는 것은 그만큼 좋은 컴퓨터를 써야 한다는 것.
- 자신의 문제에 따라 적합한 구조를 응용하는 것이 중요함.
- AlexNet (2012)
- 2012년 컴퓨터 비전분야의 올림픽 같은 ILSVRC에서 1위 차지함.
- 의미있는 성능을 낸 첫 번째 합성곱 신경망. CNN이 세간의 주목을 받게 됨.
- Dropout과 Image augmentation 기법을 효과적으로 적용하여 딥러닝에 많은 기여를 함.
- VGGNet (2014)
- 큰 특징은 없지만 파라미터 개수가 많고 모델의 깊이가 깊은 엄청 Deep한 모델로 잘 알려짐.
- (컴퓨터 성능이 좋아진 결과)
- 요즘에도 처음 모델 설계 시 전이학습 등을 통해 가장 먼저 테스트하는 모델로 사용.
- 간단한 방법론으로 좋은 성적을 내서 유명해짐
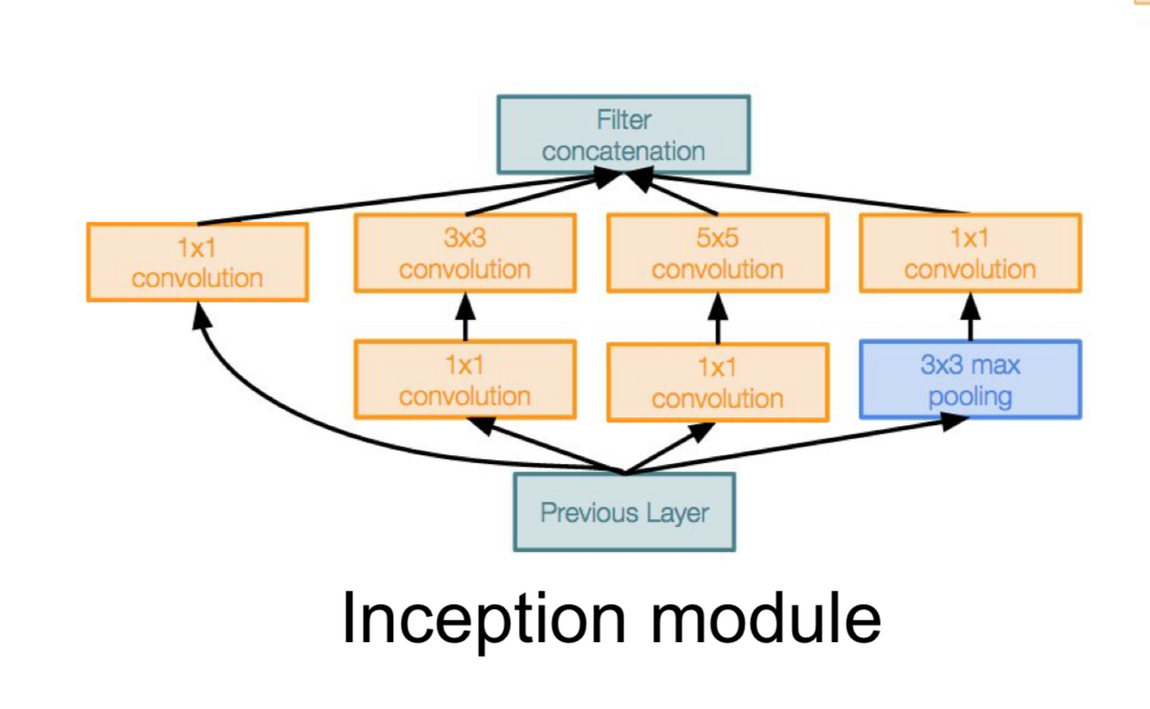
- GoogLeNet(=Inception V3) (2015)
- 합성곱 신경망의 아버지 르쿤 교수님이 구글에서 개발한 합성곱 신경망 구조
- AlexNet 이후 층을 더 깊게 쌓아 성능을 높이려는 시도: VGGNet, GoogLeNet 등
- VGGNet보다 복잡한 구조로 널리 쓰이진 않았지만 구조 면에서 주목 받음.
- Inception module(인셉션 모듈) 구조 제안함.
- 하나의 계층에서도 여러 종류의 필터, 풀링을 도입함으로써 개별 계층을 두텁게 확장시킨 아이디어.
- 사람이 물체를 보는 방식과 비슷하다. 한번 쓱 흩고, 자세히 보는 것.
- ResNet (2015)
- Residual block을 제안함. 그래디언트가 잘 흐를 수 있도록 일종의 지름길을 만들어주는 방법.
- 인풋과 아웃풋의 차이를 학습한다. gradiant vanishing을 없애준다.
- 대부분의 경우 Residual block을 사용하면 모델의 성능이 좋아진다고 함.
- 합성곱 신경망 역사에서 큰 영향을 끼쳤고, 아직도 많이 사용되는 구조 중 하나임.
- 거의 모든 경우 Residual block 사용하며 안 쓰는 경우는 거의 없음.
- 층을 늘려도 효과가 별로 없다고 생각되면 layer 개수 줄이거나 ResNet 사용해보기.
4-5. Transfer Learning (전이 학습)
더보기

출처: https://towardsdatascience.com/a-comprehensive-hands-on-guide-to-transfer-learning-with-real-world-applications-in-deep-learning-212bf3b2f27a
01. 전이 학습
- 전이 학습: 과거 문제해결경험을 토대로 유사한 문제를 해결하도록 신경망을 학습시키는 방법
- 비교적 학습 속도가 빠르고 (빠른 수렴), 더 정확하고, 상대적으로 적은 데이터셋으로도 좋은 결과 냄.
- 따라서 실무에서도 자주 사용하는 방법.
- 흥미로운 점은 다른 형태의 데이터셋에 대해서도 효과를 보인다는 점.
- ex) 동물/사물을 분류하는 모델을 얼굴 인식 데이터셋에 학습시켜도 좋은 결과 얻을 수 있음.
- → 딥러닝에서 더욱 중요함
- 모델 설계 전에 항상 해야 할 일: 데이터셋 분석 후 바로 전이학습을 통해 성능 측정.
- 어떤 모델이 가장 좋은 성능이 나오더라. 하면 거기에서 변형된 모델로 튜닝을 한다.
- 이런 식으로 연구가 이루어지고 있음.
4-6. Recurrent Neural Networks (순환 신경망)
더보기
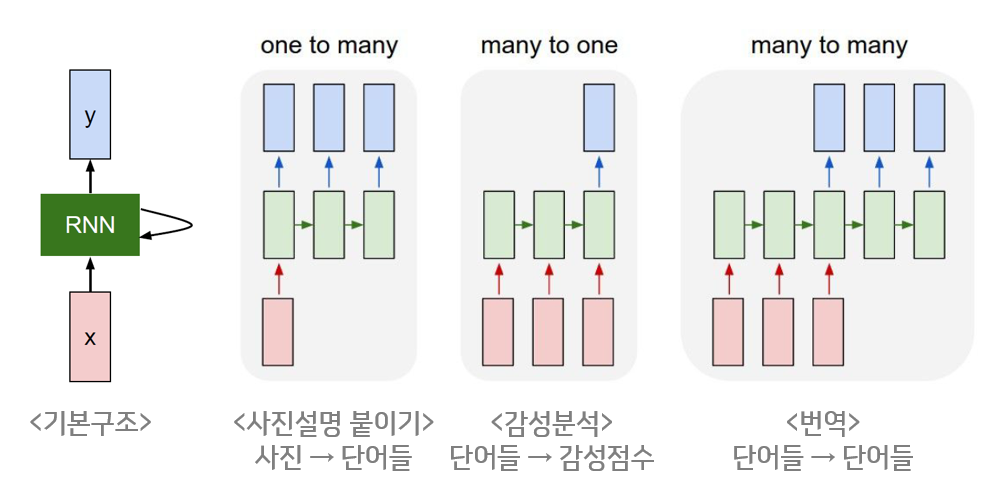
출처: https://ratsgo.github.io/natural language processing/2017/03/09/rnnlstm/
01. Recurrent Neural Networks (RNN)
- RNN: 은닉층이 순차적으로 연결되어 순환구조를 이루는 인공신경망의 한 종류.
- 길이에 관계없이 입력, 출력을 받아들일 수 있는 구조.
- 장점: 필요에 따라 다양하고 유연하게 구조 생성 가능.
- 음성, 문자 등 순차적으로 등장하는 데이터 처리에 적합한 모델
- 사용예시: 주식 및 암호화폐의 시세 예측하기, 인간과 대화하는 챗봇 만들기 등
- 번역 모델 만들 때 많이 사용되어 유명해짐.
4-7. Generative Adversarial Network (생성적 적대 신경망)
더보기

01. Generative Adversarial Network (GAN)
- GAN: 서로 적대(Adversarial)하는 관계의 2가지 모델(생성, 판별모델)을 동시에 사용하는 기술.
- 최근 딥러닝 학계에서 굉장히 핫한 분야임.
- AnimalGAN 머신이 잡음에서 동물 이미지를 만드는 방법을 GAN 작동방식으로 이해하자.
- Input Data: 랜덤으로 생성된 잡음
- Output Data: 0~1 사이의 값 (0: 가짜, 1: 진짜)
- 생성모델(위조지폐범): 경찰도 구분 못하는 진짜 같은 위조지폐를 만들자.
- 이미지가 1로 판별될수록 좋음. 보다 정교하게 Target이 1로 나오도록 해야 함.
- 타깃(1)과 예측의 차이인 손실을 줄이기 위해 Backpropagation을 이용한 weight를 조정할 것임.
- 판별모델(경찰): 진짜와 위조 지폐를 잘 구분하자.
- 진짜 이미지는 1로, 가짜 이미지는 0으로 판별할 수 있어야 함.
- 생성된 모델에서 진짜, 가짜 이미지 둘다 학습하여 예측과 타깃의 차이인 손실을 줄여야 함.
- 이렇게 에폭이 반복되면 서로 발전의 관계가 되어 원본과 구별이 어려운 가짜 이미지 생성됨.
- 보통 생성모델에 더 신경을 많이 쓴다.
- GAN을 사용한 예시들:
- CycleGAN
- StarGAN
- CartoonGAN
- DeepFake: GAN을 이용한 분야 중 가장 발전이 빠르다.
- BeautyGAN
- Toonify Yourself
4-8. CNN 실습
더보기
01. 수화 MNIST CNN으로 학습해보기
- 3주차에는 수화 MNIST를 단순한 딥러닝 모델(Deep Neural Networks, MLP)로 분류했음.
- 이번에는 CNN을 써볼 차례. 얼마나 향상되는지 확인해보자.
- CNN 학습해보기
- 1. [런타임] - [런타임 유형변경] - GPU 선택
- 2. 데이터셋 다운로드
# Kaggle API
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'key' # key
!kaggle datasets download -d datamunge/sign-language-mnist
!unzip sign-language-mnist.zip- 3. 필요한 패키지 임포트하기
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, Flatten, Dropout
# Conv2D: Convolution 연산
# MaxPooling2D: Subsampling 할 때 사용
# Flatten: 2차원을 1차원으로 펴줄 때 사용
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator # 데이터 증강(Data agmentation)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder- 4. 데이터셋 로드하기
train_df = pd.read_csv('sign_mnist_train.csv')
test_df = pd.read_csv('sign_mnist_test.csv')
# train_df.head()
# test_df.head()- 5. 라벨 분포 확인하기
# 저번과 마찬가지로 J, Z 빠졌으므로 24개의 알파벳만 나옴.
plt.figure(figsize=(16, 10))
sns.countplot(train_df['label']) # 그래프 주르륵 나온다.
plt.show()- 6. 전처리하기
- 6-1. 입력, 출력 나누기
# x 데이터를 (28, 28, 1) 크기의 이미지 형태로 변환함.
train_df = train_df.astype(np.float32)
x_train = train_df.drop(columns=['label'], axis=1).values
x_train = x_train.reshape((-1, 28, 28, 1))
y_train = train_df[['label']].values
test_df = test_df.astype(np.float32)
x_test = test_df.drop(columns=['label'], axis=1).values
x_test = x_test.reshape((-1, 28, 28, 1))
y_test = test_df[['label']].values- 6-2. 데이터 미리보기
index = 1
plt.title(str(y_train[index]))
plt.imshow(x_train[index].reshape((28, 28)), cmap='gray')
plt.show()- 6-3. One-hot 인코딩하기
encoder = OneHotEncoder()
y_train = encoder.fit_transform(y_train).toarray()
y_test = encoder.fit_transform(y_test).toarray()- 6-4. 일반화하기
# 이미지 데이터를 255로 나눴음
# 이번에는 ImageDataGenerator() 사용해서 일반화 하기
train_image_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
)
train_datagen = train_image_datagen.flow(
x=x_train,
y=y_train,
batch_size=256,
shuffle=True
)
test_image_datagen = ImageDataGenerator(
rescale=1./255
)
test_datagen = test_image_datagen.flow(
x=x_test,
y=y_test,
batch_size=256,
shuffle=False
)
index = 1
preview_img = train_datagen.__getitem__(0)[0][index]
preview_label = train_datagen.__getitem__(0)[1][index]
plt.imshow(preview_img.reshape((28, 28)))
plt.title(str(preview_label))
plt.show()- 7. 네트워크 구성하기
input = Input(shape=(28, 28, 1))
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(input)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=64, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Flatten()(hidden)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dropout(rate=0.3)(hidden)
output = Dense(24, activation='softmax')(hidden)
model = Model(inputs=input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])- 8. 모델 학습시키기
history = model.fit(
train_datagen,
validation_data=test_datagen, # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)
- 이미지 증강기법 이용해보기
- 1. 학습 데이터 증강하기
train_image_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
rotation_range=10, # 랜덤하게 이미지를 회전 (단위: 도, 0-180)
zoom_range=0.1, # 랜덤하게 이미지 확대 (%)
width_shift_range=0.1, # 랜덤하게 이미지를 수평으로 이동 (%)
height_shift_range=0.1, # 랜덤하게 이미지를 수직으로 이동 (%)
)
train_datagen = train_image_datagen.flow(
x=x_train,
y=y_train,
batch_size=256,
shuffle=True
)- 2. 검증 데이터 일반화하기
test_image_datagen = ImageDataGenerator(
rescale=1./255
)
test_datagen = test_image_datagen.flow(
x=x_test,
y=y_test,
batch_size=256,
shuffle=False
)- 3. 이미지 확인하기
index = 1
preview_img = train_datagen.__getitem__(0)[0][index]
preview_label = train_datagen.__getitem__(0)[1][index]
plt.imshow(preview_img.reshape((28, 28)))
plt.title(str(preview_label))
plt.show()- 4. 네트워크 구성하기
input = Input(shape=(28, 28, 1))
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(input)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=64, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Conv2D(filters=32, kernel_size=3, strides=1, padding='same', activation='relu')(hidden)
hidden = MaxPooling2D(pool_size=2, strides=2)(hidden)
hidden = Flatten()(hidden)
hidden = Dense(512, activation='relu')(hidden)
hidden = Dropout(rate=0.3)(hidden)
output = Dense(24, activation='softmax')(hidden)
model = Model(inputs=input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])
model.summary()- 5. 모델 학습시키기
history = model.fit(
train_datagen,
validation_data=test_datagen, # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20 # epochs 복수형으로 쓰기!
)
4-9. 전이학습 실습
더보기
01. 과일 분류에 전이학습 적용해보기
- 이미 학습된 Inception-V3로 과일의 360도 사진 분류하기
- 1. GPU 선택해서 연산속도 늘리기
- 2. 데이터셋 다운로드
import os
os.environ['KAGGLE_USERNAME'] = 'username' # username
os.environ['KAGGLE_KEY'] = 'key' # key
!kaggle datasets download -d moltean/fruits
!unzip -q fruits.zip- 3. 필요한 패키지 임포트하기
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Input, Dense, Conv2D, MaxPooling2D, Flatten, Dropout
from tensorflow.keras.optimizers import Adam, SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import OneHotEncoder- 4. 전처리하기 - 폴더에서 직접 데이터 가져와서 증강기법까지 써보기
train_datagen = ImageDataGenerator(
rescale=1./255, # 일반화
rotation_range=10, # 랜덤하게 이미지를 회전 (단위: 도, 0-180)
zoom_range=0.1, # 랜덤하게 이미지 확대 (%)
width_shift_range=0.1, # 랜덤하게 이미지를 수평으로 이동 (%)
height_shift_range=0.1, # 랜덤하게 이미지를 수직으로 이동 (%)
horizontal_flip=True # 랜덤하게 이미지를 수평으로 뒤집기
)
test_datagen = ImageDataGenerator(
rescale=1./255 # 일반화
)
train_gen = train_datagen.flow_from_directory(
'fruits-360/Training',
target_size=(224, 224), # (height, width)
batch_size=32,
seed=2021,
class_mode='categorical',
shuffle=True
)
test_gen = test_datagen.flow_from_directory(
'fruits-360/Test',
target_size=(224, 224), # (height, width)
batch_size=32,
seed=2021,
class_mode='categorical',
shuffle=False
)- 5. 데이터 확인하기
from pprint import pprint
pprint(train_gen.class_indices)
preview_batch = train_gen.__getitem__(0)
preview_imgs, preview_labels = preview_batch
plt.title(str(preview_labels[0]))
plt.imshow(preview_imgs[0])- 6. 전이학습 - 모델 가져와서 수정하기
from tensorflow.keras.applications.inception_v3 import InceptionV3
input = Input(shape=(224, 224, 3))
base_model = InceptionV3(weights='imagenet', include_top=False, input_tensor=input, pooling='max')
x = base_model.output
x = Dropout(rate=0.25)(x)
x = Dense(256, activation='relu')(x)
output = Dense(131, activation='softmax')(x)
model = Model(inputs=base_model.input, outputs=output)
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=0.001), metrics=['acc'])- 7. 모델 학습시키기
from tensorflow.keras.callbacks import ModelCheckpoint
history = model.fit(
train_gen,
validation_data=test_gen, # 검증 데이터를 넣어주면 한 epoch이 끝날때마다 자동으로 검증
epochs=20, # epochs 복수형으로 쓰기!
callbacks=[
ModelCheckpoint('model.h5', monitor='val_acc', verbose=1, save_best_only=True)
]
)- 8. 학습된 모델 로딩하기
from tensorflow.keras.models import load_model
model = load_model('model.h5')- 9. 결과 확인하기
test_imgs, test_labels = test_gen.__getitem__(100)
y_pred = model.predict(test_imgs)
classes = dict((v, k) for k, v in test_gen.class_indices.items())
fig, axes = plt.subplots(4, 8, figsize=(20, 12))
for img, test_label, pred_label, ax in zip(test_imgs, test_labels, y_pred, axes.flatten()):
test_label = classes[np.argmax(test_label)]
pred_label = classes[np.argmax(pred_label)]
ax.set_title('GT:%s\nPR:%s' % (test_label, pred_label))
ax.imshow(img)
4-10. 4주차 끝 & 숙제 설명
더보기
01. CNN으로 풍경 사진을 분류해봅시다!
- CNN으로 풍경 사진 분류하기
- 전이학습 기법을 이용하여 ResNet 모델을 가져와 빌딩, 숲, 빙하, 산 등의 사진을 분류함.
'스파르타코딩클럽 > 강의 정리' 카테고리의 다른 글
| [스파르타] Django 기초반 2주차 (완강) (0) | 2022.01.20 |
|---|---|
| [스파르타] Django 기초반 1주차 (완강) (0) | 2022.01.19 |
| [스파르타] 실전 머신러닝 적용 3주차 (완강) (0) | 2022.01.11 |
| [스파르타] 실전 머신러닝 적용 2주차 (완강) (0) | 2022.01.11 |
| [스파르타] 실전 머신러닝 적용 1주차 (완강) (0) | 2022.01.05 |
'스파르타코딩클럽/강의 정리' Related Articles
more


Comments